

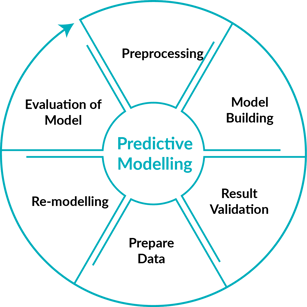
Suppose you have a predictive model which has >85% accuracy - but is the model a good model? Just based on an accuracy we can’t judge whether a model is good or not. There are several scores to check the quality of a model. The Area Under the Curve (AUC) Score plays an important role. The AUC score of a model should be at least >0.6. We can also consider Root Mean Squared Error (RMSE) score for Multinomial models. It is important to evaluate a model as per the cycle below:
I am going to discuss some possible reasons why a model turns out to be under performing and what are the best practices to build a better performing model with high accuracy.
Reasons for a model to under perform
1) Imbalance in Classes of Response Variable:
Once you have one or more classes in the response variable then that variable is imbalanced. As per my research, the thumb rule for a binary response is, if a class in the responsible variable has <10% of importance this can cause issues. This is common in Health Care, Advertising and Fraud Detection.
2) Artificial Balancing of Response Variable:
We can always balance the data in the training set. We balance the data by sampling the training dataset. But there are also some potential pitfalls with this technique. We should not use sampling on the test data because using original, unbalanced test data gives us honest model performance. Same rule applies to cross validation data set.
3) Categorical Data:
Real data in every industry contains categorical data. Sometimes you might end up having all categorical columns in the data. To obtain some predictions, we are forced to use some variables which have more than two categories. For example, in Health Care you might end up with a column of diagnostic and a column procedure codes which have over 1000 categories. There are many diagnostic and procedure codes in that column that only occur small number of times. These codes are not very useful to the model and need to be managed.
4) Missing Data:
There are different kinds of missing data.
- Unavailable data which is valid for the model or observation, but not available in the dataset.
- Data which has been removed from the data because it hasn’t reached the quality of that variable observation.
- NA and NAN values which are not applicable to that particular variable.
5) Outliers and extreme values:
The response variables of a real world dataset contain outliers and extreme values. These outliers can cause errors in measurements of our predictive model. They will have disproportionate weight values on our predictive model. MSE values will be affected because of these outliers. If we are using boosting models, these outliers have major impact on our model as boosting models tend to spend modelling effort to fit these outliers.
6) Leakage of Data:
If we allow the model to use the information that may not be available in a production setting, then it is known as data leakage. This leads to overfitting of the model. The predictions might be inconsistent when we try to fit the model. This leads to incorrect insights to business end.
Best practices to improve the model performance and accuracy
1) Bias and Variance:
Achieving the balance between bias and variance is a key remedy to achieve a better predictive model. If we can reduce the variance and make our model tolerate some bias, then it leads to a better predictive model.
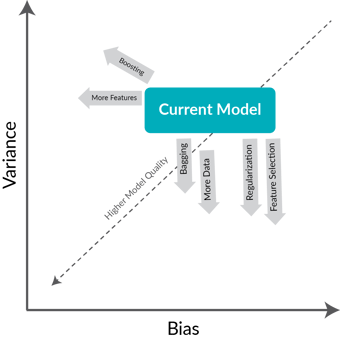
2) Sampling Variables:
We can manually sample the majority and minority classes by duplicating or by using the weights of rows. Up-sampling should be used for minority classes and Down-sampling should be used for majority classes.
3) Categorical data:
For the categorical data problem, we should have a good knowledge about our dataset hierarchically. This knowledge helps us to reduce the number of categories with higher-level mapping.
4) Missing data:
If we have a variable with the most missing data we can either ignore that variable or we can segment and use some methods to fill those missing values. Methods such as taking the mean or median or mode values of that variable and filling the missing values with them.
5) Outliers:
We might apply transformation techniques to reduce the outliers impact on our model. We should validate the data by understanding the importance of those outliers.
Conclusion
So how do we know that our model is a good and accurate model? We can apply the above remedies while building a predictive model. By doing so we can save more time and we can achieve a reliable predictive model. In case of real world datasets, we might face bigger problems while building a predictive model. But, if we keep the above mentioned reasons in mind and try to implement them while building our model, we can achieve a better predictive model with good accuracy.